

编者按 —— 本文是以下系列博文中的一篇(共十篇):
- 生产级 Kubernetes 助您降低复杂性
- 如何通过高级流量管理提高 Kubernetes 的弹性
- 如何提高 Kubernetes 环境的可视性(本文)
- 使用流量管理工具保护 Kubernetes 的六种方法
- Ingress Controller 选型指南,第一部分:确定需求
- Ingress Controller 选型指南,第二部分:评估风险和技术前瞻性
- Ingress Controller 选型指南,第三部分:开源、默认和商用版本能力对比
- Ingress Controller 选型指南,第四部分:NGINX Ingress Controller 选项
- 如何选择 Service Mesh
- NGINX Ingress Controller 在动态 Kubernetes 云环境中的性能测试
您还可以免费下载整套博文集结成的电子书:《Kubernetes:从测试到生产》。
虽然采用微服务可以改善数字体验,但微服务架构也会让这些体验变得更加脆弱。在开发人员紧锣密鼓地推出新应用的同时,您的架构可能会带来更大的中断风险和安全隐患,您可能还要耗费时间进行低效的故障排除或修复可预防的问题。本文是生产级 Kubernetes 系列博文的第二篇,探讨了如何在微服务环境中通过流量可视化来降低复杂性并提高安全性。
实现可视化,获得洞察力
首先,我们来看几个定义:
- 可视化 —— 能够看到或被看到的状态
- 洞察 —— 对人或物拥有深刻的理解
StackRox 2020 年的一项调查显示,75% 的 Kubernetes 用户认为可视化是一项“必备”能力。我们也认为可视化是 Kubernetes 环境的一个关键要素,毕竟要想弄清其中林林总总的部署项目,谈何容易。然而,在 F5 的《2021 年应用策略现状》(SOAS) 报告中,95% 的受访者表示,尽管他们拥有丰富的数据,但对于保护和发展基础架构和业务所需的应用的性能、安全性和可用性,他们仍然无法获取“洞察”。洞察为何如此重要?如何获得洞察?
洞察可帮助您:
- 检测漏洞和潜在攻击向量,增强安全性与合规性
- 先于客户发现问题,减少中断和停机时间
- 查找应用问题的根源,提高故障排除效率
- 确认流量被正确地路由
- 准确了解 Kubernetes 环境中的运行项目及其是否得到合理配置和保护
- 根据延迟和性能历史记录确定您是否使用了适当的资源数量
- 基于过去的流量模式预测季节性需求
- 根据响应时间衡量性能,并根据服务等级协议 (SLA) 追踪性能,同时用作预警系统,防止问题影响用户体验
要获得洞察力,您需要两种类型的可视化数据:实时数据和历史数据。实时数据可帮助您诊断当前问题的来源,而历史数据可帮助您辨别正常与异常。这两种类型的可视化来源相结合,可提供关于应用和 Kubernetes 性能的关键洞察。
与其他技术投资一样,您还需要制定策略来帮助您实现相关收益。SOAS 报告还指出,出于企业多方面的原因,例如招聘和员工发展、战略和流程以及数据用途、使用情形和使用人员的分歧,人们未能获得宝贵的洞察。调查结果包括以下三方面:
- 相关技能 —— 高素质技术专业人员短缺已经不是什么秘密,47% 的受访者表示,他们很难招到想要的人才。
- 数据共享计划 —— 只有 12% 的受访者构建了向业务决策者报告数据的流程和策略,以便让他们了解拥有弹性的技术(或缺乏弹性的技术)对业务的影响。
- 可视化的目的 —— 大多数受访者被动地使用遥测技术(即进行故障排除),而只有 24% 的受访者主动使用数据和洞察监控潜在的性能下降问题,16% 的受访者主动跟踪 SLA 性能。
下文将重点探讨技术方面的洞察。后续我们将发布有关战略、流程及其他主题的文章,敬请关注。
NGINX 如何助您一臂之力
我们知道大多数 Kubernetes 部署环境 已经有一个监控工具了,不再需要其他工具了。为此,我们提供了 NGINX Plus API,既可帮您轻松导出指标数据,也可与 OpenTracing 以及 Grafana 和 Prometheus 等热门工具相集成,从而为您提供集群内性能的全面洞察。通过深度跟踪,您可以有针对性地获得应用性能和可用性的洞察,从而了解请求在微服务应用中的处理过程。
-
出入向(南北向)流量洞察
NGINX Ingress Controller 提供了关于进出 Kubernetes 集群流量的洞察。基于 NGINX 开发的热门 Ingress Controller 一共有三个,您知道吗?这三个并非都可以投用生产环境,选择错误可能会适得其反,导致微服务策略更加复杂。我们的博文 《Ingress Controller 选型指南,第四部分:NGINX Ingress Controller 选项》对各个选项进行了比较,能够帮助您做出最能满足需求的决策。
- 东西向流量洞察
NGINX Service Mesh 对容器化应用之间的流量提供了相关洞察。
请继续阅读,看看我们如何帮助您解决两个常见问题:
如欲查看该技术的实际应用,请观看下方 NGINX 和 Grafana 专家进行的直播演示和问答环节。他们演示了如何实时监控关键负载均衡和性能指标、将指标导出到 Prometheus,并创建了一个带有累积性能视图的 Grafana 仪表盘。

问题1:应用运行很慢(或崩溃了!)
您有没有想过可能遭到了 DDOS 攻击?用户是否报告了网站的错误?您只有在找到问题所在之后才能着手解决问题。
-
借助 NGINX Ingress Controller 进行实时监控
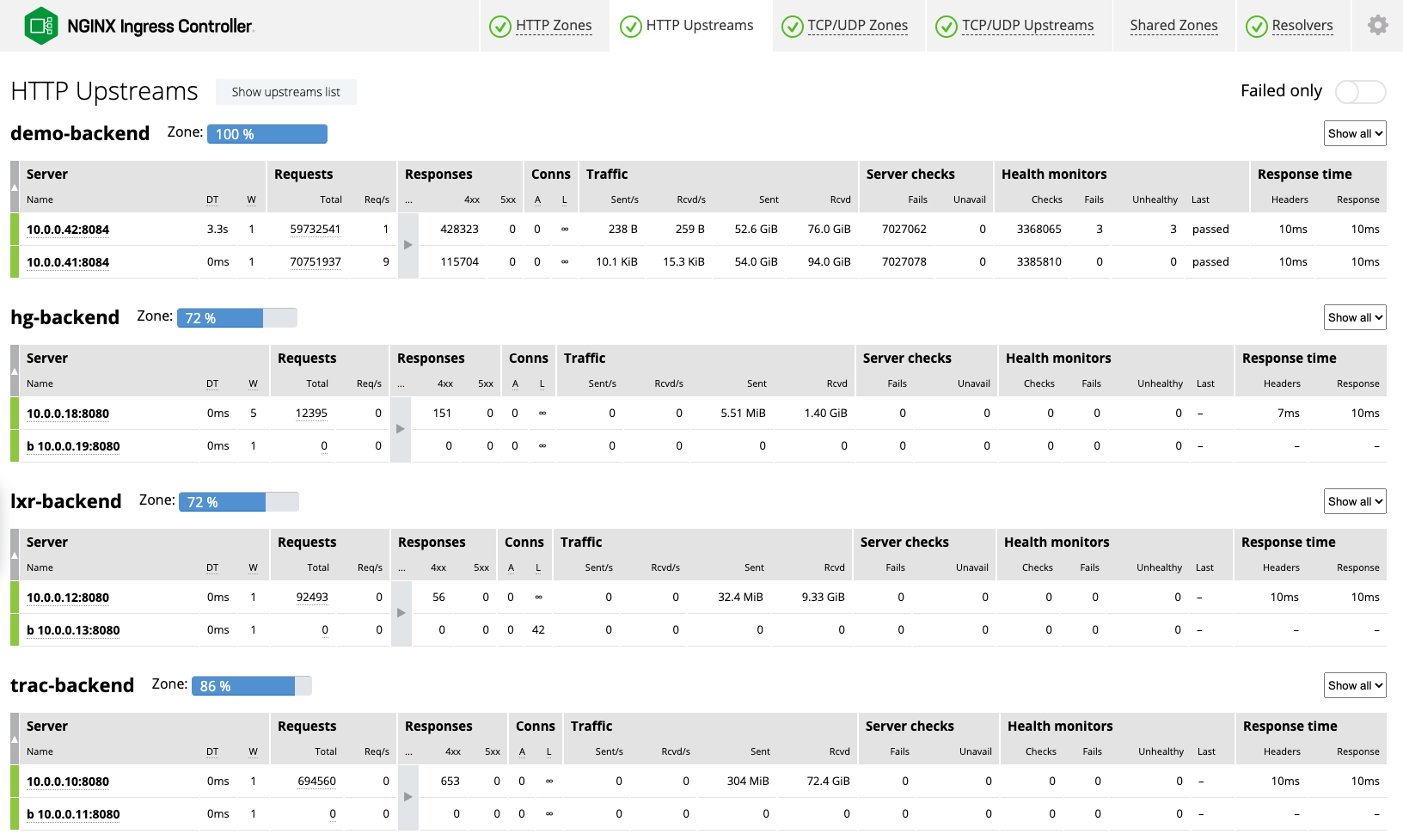
基于 NGINX Plus 的 NGINX Ingress Controller 提供了一个实时活动监控仪表盘(由 NGINX Plus API 提供支持),可显示数百个关键负载和性能指标。仪表盘可以提供细粒度信息,甚至细化到单个 pod 级别,可帮助您快速、轻松地衡量应用响应时间,并诊断问题的来源。如果您的 Kubernetes 环境不断增长,那么每个新增的 NGINX Ingress Controller 实例会自动获得新仪表盘。例如,HTTP 上游 (HTTP Upstreams) 选项卡上的两列直观地显示了应用和基础架构状态:
- 请求 —— 如果每秒请求数 (Req/s) 降至给定应用标准以下(例如,每秒 5 个请求,而正常请求数为 40),则表示 Ingress Controller 或应用的配置可能不正确。
- 响应时间 —— o如果响应时间为 10 毫秒 (ms) 或更少,则表示运行状况良好。延迟超过 30-40 毫秒表示上游应用出现问题。

- NGINX Ingress Controller 的基本状态
配合使用NGINX 开源版,NGINX Ingress Controller 提供了一个状态页面,报告八个基本指标。 - NGINX Service Mesh 的 OpenTracing
NGINX Service Mesh 通过 NGINX OpenTracing 模块支持 OpenTracing。在撰写本文时,NGINX OpenTracing 模块支持 DataDog、LightStep、Jaeger 和 Zipkin。
问题2:集群或平台耗尽资源
出现了 HTTP 错误?503 和 40x 错误表示存在资源问题,而 502 表示配置变更不成功。您可以使用历史数据来诊断可能会出现资源耗尽的地方。
- 借助 NGINX Ingress Controller 进行日志记录
诊断网络问题的第一步是查看 NGINX Ingress Controller 日志,其中每个日志条目都使用相关的 Kubernetes 服务注释。日志的错误条目会标识相关服务。日志包含了流经 Ingress Controller 的所有流量的详细信息,包括时间戳、源 IP 地址和响应状态码。您还可以将日志导出到流行的聚合器中,例如 DataDog、Grafana 和 Splunk。 -
Prometheus 指标
NGINX Ingress Controller 最受欢迎的特性之一是其不断扩展的 Prometheus 指标列表,其中包含网络性能和 Ingress Controller 流量指标。基于 NGINX Plus 的 NGINX Ingress Controller 能够导出一系列相关指标,涵盖连接、缓存、由 NGINX worker 组(在内存区共享数据)处理的 HTTP 和 TCP/UDP 流量、由后端服务器组处理的 HTTP 和 TCP/UDP 流量等。NGINX Service Mesh 部署了一个 Prometheus 服务器,该服务器使用 NGINX Plus API 从 NGINX Service Mesh sidecar 和 NGINX Ingress Controller pod 获取指标。如果您希望使用现有的 Prometheus 部署,我们还提供 scrape 配置,以供您添加到 Prometheus 配置文件。
- Grafana 仪表盘
我们为 NGINX Ingress Controller 和 NGINX Service Mesh 提供了官方 Grafana 仪表盘,能够将 Prometheus Exporter 暴露出来的指标数据可视化。用户非常重视数据的粒度,包括精确到毫秒的详细信息、逐日覆盖和流量峰值。例如,NGINX Service Mesh 仪表盘可以显示任何一个服务或 pod 的流量以及被监控的活动 pod 的数量,以标示 pod 的运行负载情况。
NGINX 助您做好生产准备
生产就绪的 NGINX Ingress Controller(基于 NGINX Plus)提供 30 天免费试用版,其中包括可以保护容器化应用的 NGINX App Protect。您可前往 f5.com 下载终身免费的 NGINX Service Mesh。